Overview
This document will guide you through some data analysis tasks with a focus on fitting tree-based models and training them. We’ll also (re)-visit some other topics.
While this is in some sense a stand-alone analysis, I assume that you have worked through the Data Analysis exercise and are familiar with the dataset and all the things we discovered during the cleaning process. We’ll use the same dataset here but focus on a different outcome. Other than that, the way to work through the exercise is like in the Data Analysis exercise, namely by writing/completing the missing code.
Project setup
We need a variety of different packages, which are loaded here. Install as needed. For this analysis, we’ll again use the caret package. If you use others, load them here.
library('tidyr')
library('dplyr')
library('forcats')
library('ggplot2')
library('knitr')
library('doParallel')
library('rpart')
library('rpart.plot')
library('mda')
library('ranger')
library('e1071')
library('tidyverse')
library('visdat')
library('ggridges')
library('gridExtra')
library('nnet')
library('gbm')
library('mlr')
library('caret')
library('expss')Data loading and cleaning
We will again use the Norovirus dataset.
Looking at the outcome
For this analysis, we consider as our main outcome of interest the season. This is a categorical outcome with more than 2 categories, something we haven’t looked at before. Because it’s more than 2 categories, a basic logistic model won’t work. Fortunately, tree-based models can deal with multiple categories.
#write code to take a look at the outcome variable (season)
# View(data_raw$season)
table(data_raw$season) # there are 67 blank##
## Fall Spring Summer Winter
## 67 164 222 126 443## [1] "character"We already knew from previous explorations that some entries do not have a season. We could either code them as “other” and keep them in the model, or remove them. Since it’s hard to see any potential scientific reason why there should be a correlation between an “other” season and some variable, we’ll remove it here.
We also notice that while winter is dominant (makes sense, we know that norovirus is more common in winter), we got a decent number of outbreaks for each season, so we shouldn’t have a problem with (un)balanced data.
#write code that removes all observations that have an empty/missing value for season
temp2 <- data_raw[data_raw$season != "", ]
table(temp2$season)##
## Fall Spring Summer Winter
## 164 222 126 443#then drop the empty level and check that you have 4 categories for season left
temp2$season <- factor(temp2$season) # season was a character class before, so no need to drop an empty level. Making it factor now
levels(temp2$season)## [1] "Fall" "Spring" "Summer" "Winter"Selecting predictors
We will pick similar variables as previously, but with some changes. Keep the following variables: Action1, CasesAll, Country, Deaths, EndMonth, GG2C4, Hemisphere, Hospitalizations, MeanD1, MeanI1, MedianD1, MedianI1, OBYear, Path1, RateAll, RiskAll, Season, Setting, StartMonth, State, Trans1, Vomit.
# write code that retains the above mentioned variables
# sort(names(temp2))
temp3 <- temp2 %>% select(Action1, CasesAll, Country, Deaths, EndMonth, gg2c4, Hemisphere, Hospitalizations, MeanD1, MeanI1, MedianD1, MedianI1, OBYear, Path1, RateAll, RiskAll, season, Setting_1, StartMonth, State, Trans1, Vomit)Cleaning predictors
We’ll have to perform the usual cleaning steps. You might have realized by now that even for the same dataset, cleaning steps can differ based on the outcome (and as you see below, the model).
Let’s first check for missing values.

## $Action1
## [1] 0
##
## $CasesAll
## [1] 5
##
## $Country
## [1] 0
##
## $Deaths
## [1] 42
##
## $EndMonth
## [1] 0
##
## $gg2c4
## [1] 0
##
## $Hemisphere
## [1] 0
##
## $Hospitalizations
## [1] 42
##
## $MeanD1
## [1] 0
##
## $MeanI1
## [1] 0
##
## $MedianD1
## [1] 0
##
## $MedianI1
## [1] 0
##
## $OBYear
## [1] 0
##
## $Path1
## [1] 0
##
## $RateAll
## [1] 104
##
## $RiskAll
## [1] 116
##
## $season
## [1] 0
##
## $Setting_1
## [1] 0
##
## $StartMonth
## [1] 0
##
## $State
## [1] 0
##
## $Trans1
## [1] 0
##
## $Vomit
## [1] 1Most of the missing data are in RiskAll (N = 116, 12.15% of records). Most records that have data missing for RiskAll also have data missing for RateAll (N = 104, 10.89% of records). Also missing some data for Hospitalizations (N = 42), Deaths (N = 42), and CasesAll (N = 5), and Vomit (N = 1).
Looks like none of the new variables we included had a ton of missing, so we would probably be ok just removing any observation that has missing data. However, tree-based models can deal with missing data in predictors. Therefore, we’ll keep them for now. We’ll later compare how the model does or does not change if we remove those observations.
Let’s make sure everything has the right format (numeric/integer/factor). Adjust/recode variables as needed. You will likely find that as you convert OBYear to numeric, something doesn’t quite work. Take a look. Fix by removing the observation with the troublesome entry, then convert to numeric. Finally, remove the observations that have 0 as OByear - there are more than 1 now.
#write code that cleans OBYear, convert it to numeric. Remove observations with OBYear = 0.
table(temp3$OBYear) # there is a record '2002-2007'##
## 0 1983 1990 1992 1993 1994 1995
## 1 1 1 1 6 15 8
## 1996 1997 1998 1999 2000 2001 2002
## 10 37 76 80 59 46 134
## 2002-2007 2003 2004 2005 2006 2007 2008
## 1 91 114 66 127 33 15
## 2009 2010
## 17 16temp4 <- temp3[temp3$OBYear != "2002-2007", ]
temp4$OBYear <- as.integer(temp4$OBYear)
temp5 <- temp4[temp4$OBYear != 0, ]
#also convert any other variables as needed
glimpse(temp5)## Observations: 953
## Variables: 22
## $ Action1 <chr> "Unspecified", "Unspecified", "Unspecified", "U…
## $ CasesAll <int> 15, 65, 27, 4, 15, 6, 40, 10, 116, 45, 184, 191…
## $ Country <chr> "Japan", "USA", "Other", "Other", "Other", "Oth…
## $ Deaths <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
## $ EndMonth <int> 12, 9, 0, 0, 0, 0, 0, 0, 11, 11, 11, 11, 12, 0,…
## $ gg2c4 <chr> "Yes", "", "Yes", "", "Yes", "", "", "", "Yes",…
## $ Hemisphere <chr> "Northern", "Northern", "Northern", "Northern",…
## $ Hospitalizations <int> 0, 0, 0, 0, 0, 0, 0, 0, 5, 10, 3, 0, 0, 0, 0, 0…
## $ MeanD1 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 24, 0, 0, 0…
## $ MeanI1 <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
## $ MedianD1 <dbl> 0, 36, 0, 0, 0, 0, 0, 0, 0, 48, 37, 24, 0, 0, 0…
## $ MedianI1 <int> 0, 37, 0, 0, 0, 0, 0, 0, 0, 31, 34, 33, 0, 0, 0…
## $ OBYear <int> 1999, 1998, 2006, 2006, 2006, 2006, 2006, 2006,…
## $ Path1 <chr> "No", "No", "Unspecified", "Unspecified", "Unsp…
## $ RateAll <dbl> 0.000000, 39.814815, 20.769231, 100.000000, 60.…
## $ RiskAll <dbl> 0.00000, 108.00000, 130.00000, 4.00000, 25.0000…
## $ season <fct> Fall, Fall, Fall, Fall, Fall, Fall, Fall, Fall,…
## $ Setting_1 <chr> "Daycare Center", "Boxed lunch, football game",…
## $ StartMonth <int> 11, 9, 9, 10, 11, 11, 11, 11, 11, 11, 11, 11, 1…
## $ State <chr> "0", "NC, FL", "0", "0", "0", "0", "0", "0", "0…
## $ Trans1 <chr> "Unspecified", "Foodborne", "Foodborne", "Foodb…
## $ Vomit <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,…A few comments:
There was supposed to be more than one OBYear = 0, but I only found one.
There are gg2c4 values that are blank, and will need to be converted to “No”
I will convert character classes to factors after I’ve finished cleaning the data
There are some values of 0 for State–will need to fix that
- Seems Vomit should be a factor
Look at the data to see what else we need to do.
## 'data.frame': 953 obs. of 22 variables:
## $ Action1 : chr "Unspecified" "Unspecified" "Unspecified" "Unspecified" ...
## $ CasesAll : int 15 65 27 4 15 6 40 10 116 45 ...
## $ Country : chr "Japan" "USA" "Other" "Other" ...
## $ Deaths : int 0 0 0 0 0 0 0 0 0 0 ...
## $ EndMonth : int 12 9 0 0 0 0 0 0 11 11 ...
## $ gg2c4 : chr "Yes" "" "Yes" "" ...
## $ Hemisphere : chr "Northern" "Northern" "Northern" "Northern" ...
## $ Hospitalizations: int 0 0 0 0 0 0 0 0 5 10 ...
## $ MeanD1 : num 0 0 0 0 0 0 0 0 0 0 ...
## $ MeanI1 : int 0 0 0 0 0 0 0 0 0 0 ...
## $ MedianD1 : num 0 36 0 0 0 0 0 0 0 48 ...
## $ MedianI1 : int 0 37 0 0 0 0 0 0 0 31 ...
## $ OBYear : int 1999 1998 2006 2006 2006 2006 2006 2006 2004 1993 ...
## $ Path1 : chr "No" "No" "Unspecified" "Unspecified" ...
## $ RateAll : num 0 39.8 20.8 100 60 ...
## $ RiskAll : num 0 108 130 4 25 ...
## $ season : Factor w/ 4 levels "Fall","Spring",..: 1 1 1 1 1 1 1 1 1 1 ...
## $ Setting_1 : chr "Daycare Center" "Boxed lunch, football game" "buffet" "restaurant" ...
## $ StartMonth : int 11 9 9 10 11 11 11 11 11 11 ...
## $ State : chr "0" "NC, FL" "0" "0" ...
## $ Trans1 : chr "Unspecified" "Foodborne" "Foodborne" "Foodborne" ...
## $ Vomit : int 1 1 1 1 1 1 1 1 1 1 ...## Action1 CasesAll Country Deaths
## Length:953 Min. : 1 Length:953 Min. :0.00000
## Class :character 1st Qu.: 9 Class :character 1st Qu.:0.00000
## Mode :character Median : 25 Mode :character Median :0.00000
## Mean : 129 Mean :0.05379
## 3rd Qu.: 64 3rd Qu.:0.00000
## Max. :32150 Max. :9.00000
## NA's :5 NA's :42
## EndMonth gg2c4 Hemisphere Hospitalizations
## Min. : 0.000 Length:953 Length:953 Min. : 0.0000
## 1st Qu.: 0.000 Class :character Class :character 1st Qu.: 0.0000
## Median : 0.000 Mode :character Mode :character Median : 0.0000
## Mean : 2.559 Mean : 0.7113
## 3rd Qu.: 4.000 3rd Qu.: 0.0000
## Max. :12.000 Max. :125.0000
## NA's :42
## MeanD1 MeanI1 MedianD1 MedianI1
## Min. : 0.000 Min. : 0.0000 Min. : 0.000 Min. : 0.000
## 1st Qu.: 0.000 1st Qu.: 0.0000 1st Qu.: 0.000 1st Qu.: 0.000
## Median : 0.000 Median : 0.0000 Median : 0.000 Median : 0.000
## Mean : 1.558 Mean : 0.7125 Mean : 2.611 Mean : 1.703
## 3rd Qu.: 0.000 3rd Qu.: 0.0000 3rd Qu.: 0.000 3rd Qu.: 0.000
## Max. :273.600 Max. :48.0000 Max. :235.200 Max. :65.000
##
## OBYear Path1 RateAll RiskAll
## Min. :1983 Length:953 Min. : 0.00 Min. : 0.0
## 1st Qu.:2000 Class :character 1st Qu.: 0.00 1st Qu.: 0.0
## Median :2003 Mode :character Median : 16.50 Median : 20.5
## Mean :2002 Mean : 27.04 Mean : 399.7
## 3rd Qu.:2005 3rd Qu.: 49.00 3rd Qu.: 110.8
## Max. :2010 Max. :105.00 Max. :35000.0
## NA's :103 NA's :115
## season Setting_1 StartMonth State
## Fall :164 Length:953 Min. : 0.000 Length:953
## Spring:222 Class :character 1st Qu.: 2.000 Class :character
## Summer:125 Mode :character Median : 5.000 Mode :character
## Winter:442 Mean : 5.894
## 3rd Qu.:10.000
## Max. :12.000
##
## Trans1 Vomit
## Length:953 Min. :0.0000
## Class :character 1st Qu.:0.0000
## Mode :character Median :1.0000
## Mean :0.5074
## 3rd Qu.:1.0000
## Max. :1.0000
## NA's :1Some issues we noted previously: We need to remove the Unspecified entry in Hemisphere and recode Action1 and Path1 as described in the Data Analysis exercise, i.e., from Unknown to Unspecified. Also, we want to group the Setting_1 variable into just Restaurant and Other. Again, remember that there are restaurant and Restaurant values, so you need to fix that too.
We’ll also recode the gg2c4 blank entries to “No”. We further note that Action1 has a single No entry. Let’s remove that observation to prevent potential problems during cross-validation.
Let’s also lump country together, make 3 categories, Japan, USA, and Other.
As discussed previously, it makes sense to move the Waterborne to the Environmental in the Trans1 variable. It also turns out that most outbreaks have no information for state, so best to drop the State variable.
Finally, move the outcome into the first column.
# write code that performs the actions described above
# Drop records with 'Unspecified' for 'Hemisphere'
unique(temp5$Hemisphere) # I don't see any "Unspecified"## [1] "Northern" "Southern"# View(data_raw[data_raw$Hemisphere=="Unspecified", ]) # oh, so the records with "Unspecified" were already dropped earlier
# Combine 'Unknown' and 'Unspecified'
table(temp5$Action1)##
## No Unknown Unspecified Yes
## 1 1 742 209##
## No Unspecified Yes
## 1 743 209##
## No Unknown Unspecified Yes
## 197 3 675 78##
## No Unspecified Yes
## 197 678 78# Reclassify 'Setting1'
# unique(temp5$Setting_1) # I commented this out after looking at it, because it would take too much space in the output
(c("Sub Restaruant", "Resaurant", unique(temp5$Setting_1)[grep("restaurant", unique(temp5$Setting_1), ignore.case = TRUE)])) # These are the 12 categories that can be considered "Restaurant"## [1] "Sub Restaruant"
## [2] "Resaurant"
## [3] "restaurant"
## [4] "take-out restaurant"
## [5] "annual festival, oyster roast, banquet, restaurant, church supper"
## [6] "Restaurant"
## [7] "Catering service in Restaurant"
## [8] "restaurant in Cabarrus county"
## [9] "restaurant in Clay county"
## [10] "restaurant in Northern Territory"
## [11] "Shared meal at a restaurant"
## [12] "restaurants, sports and community clubs, and a private function"
## [13] "restaurant; catered party"temp6 <- temp5 %>%
mutate(Setting_1 = ifelse(Setting_1 %in% c("Sub Restaruant", "Resaurant", unique(temp5$Setting_1)[grep("restaurant", unique(temp5$Setting_1), ignore.case = TRUE)]), "Restaurant", "Other"))
table(temp6$Setting_1) #188 Restaurant, 765 Other##
## Other Restaurant
## 765 188# Change gg2c4 blank entries to "No"
temp6$gg2c4[temp6$gg2c4==""] <- "No"
table(temp6$gg2c4) # 676 No, 277 Yes##
## No Yes
## 676 277# Remove the observation for which Action1 is "No"
temp6 <- temp6 %>%
filter(Action1 != "No")
# Combine Countries into 3 groups: Japan/USA/Other
temp6$Country[!temp6$Country %in% c("Japan", "USA")] <- "Other"
# Move the Waterborne into the environmental transmission
temp6$Trans1[temp6$Trans1=="Waterborne"] <- "Environmental" # changed 72 entries
# Drop the 'state' variable
temp6$State <- NULL
# Check the data again
glimpse(temp6)## Observations: 952
## Variables: 21
## $ Action1 <chr> "Unspecified", "Unspecified", "Unspecified", "U…
## $ CasesAll <int> 15, 65, 27, 4, 15, 6, 40, 10, 116, 45, 184, 191…
## $ Country <chr> "Japan", "USA", "Other", "Other", "Other", "Oth…
## $ Deaths <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
## $ EndMonth <int> 12, 9, 0, 0, 0, 0, 0, 0, 11, 11, 11, 11, 12, 0,…
## $ gg2c4 <chr> "Yes", "No", "Yes", "No", "Yes", "No", "No", "N…
## $ Hemisphere <chr> "Northern", "Northern", "Northern", "Northern",…
## $ Hospitalizations <int> 0, 0, 0, 0, 0, 0, 0, 0, 5, 10, 3, 0, 0, 0, 0, 0…
## $ MeanD1 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 24, 0, 0, 0…
## $ MeanI1 <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
## $ MedianD1 <dbl> 0, 36, 0, 0, 0, 0, 0, 0, 0, 48, 37, 24, 0, 0, 0…
## $ MedianI1 <int> 0, 37, 0, 0, 0, 0, 0, 0, 0, 31, 34, 33, 0, 0, 0…
## $ OBYear <int> 1999, 1998, 2006, 2006, 2006, 2006, 2006, 2006,…
## $ Path1 <chr> "No", "No", "Unspecified", "Unspecified", "Unsp…
## $ RateAll <dbl> 0.000000, 39.814815, 20.769231, 100.000000, 60.…
## $ RiskAll <dbl> 0.00000, 108.00000, 130.00000, 4.00000, 25.0000…
## $ season <fct> Fall, Fall, Fall, Fall, Fall, Fall, Fall, Fall,…
## $ Setting_1 <chr> "Other", "Other", "Other", "Restaurant", "Other…
## $ StartMonth <int> 11, 9, 9, 10, 11, 11, 11, 11, 11, 11, 11, 11, 1…
## $ Trans1 <chr> "Unspecified", "Foodborne", "Foodborne", "Foodb…
## $ Vomit <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,…temp6 <- temp6 %>%
dplyr::mutate_if(is.character, as.factor)
temp6$Vomit <- factor(temp6$Vomit)
summary(temp6)## Action1 CasesAll Country Deaths
## Unspecified:743 Min. : 1.0 Japan:371 Min. :0.00000
## Yes :209 1st Qu.: 9.0 Other:475 1st Qu.:0.00000
## Median : 25.0 USA :106 Median :0.00000
## Mean : 129.0 Mean :0.05385
## 3rd Qu.: 63.5 3rd Qu.:0.00000
## Max. :32150.0 Max. :9.00000
## NA's :5 NA's :42
## EndMonth gg2c4 Hemisphere Hospitalizations
## Min. : 0.000 No :676 Northern:872 Min. : 0.0000
## 1st Qu.: 0.000 Yes:276 Southern: 80 1st Qu.: 0.0000
## Median : 0.000 Median : 0.0000
## Mean : 2.555 Mean : 0.7121
## 3rd Qu.: 4.000 3rd Qu.: 0.0000
## Max. :12.000 Max. :125.0000
## NA's :42
## MeanD1 MeanI1 MedianD1 MedianI1
## Min. : 0.00 Min. : 0.0000 Min. : 0.000 Min. : 0.000
## 1st Qu.: 0.00 1st Qu.: 0.0000 1st Qu.: 0.000 1st Qu.: 0.000
## Median : 0.00 Median : 0.0000 Median : 0.000 Median : 0.000
## Mean : 1.56 Mean : 0.7132 Mean : 2.614 Mean : 1.705
## 3rd Qu.: 0.00 3rd Qu.: 0.0000 3rd Qu.: 0.000 3rd Qu.: 0.000
## Max. :273.60 Max. :48.0000 Max. :235.200 Max. :65.000
##
## OBYear Path1 RateAll RiskAll
## Min. :1983 No :197 Min. : 0.00 Min. : 0.0
## 1st Qu.:2000 Unspecified:677 1st Qu.: 0.00 1st Qu.: 0.0
## Median :2003 Yes : 78 Median : 16.50 Median : 20.5
## Mean :2002 Mean : 27.04 Mean : 399.7
## 3rd Qu.:2005 3rd Qu.: 49.00 3rd Qu.: 110.8
## Max. :2010 Max. :105.00 Max. :35000.0
## NA's :102 NA's :114
## season Setting_1 StartMonth Trans1
## Fall :164 Other :764 Min. : 0.000 Environmental : 83
## Spring:222 Restaurant:188 1st Qu.: 2.000 Foodborne :373
## Summer:125 Median : 5.000 Person to Person:150
## Winter:441 Mean : 5.894 Unknown : 63
## 3rd Qu.:10.000 Unspecified :283
## Max. :12.000
##
## Vomit
## 0 :469
## 1 :482
## NA's: 1
##
##
##
## d <- temp6 # This is the final dataset
d$season <- factor(d$season, c("Spring", "Summer", "Fall", "Winter"))
d <- d %>%
dplyr::select(season, everything())
d <- droplevels(d)
# at the end, use the droplevels() command to remove empty factor levelsThere was no need to remove records of “Unspecified” for the “Hemisphere” variable, because there were no such entries. Turns out, there were two “Unspecified” in the original data but one record had a blank entry for “Season” (so was discarded) and another had OBYear = 0 (so was discarded).
Data visualization
We know our data fairly well by now, so we might not discover much new in any plots, but it’s always good to do them anyway. Let’s create a few plots showing the outcome and the predictors. We’ll start with the continuous predictors. I suggest scatter/box/violin plots with the outcome on the x-axis.
# Write code that produces plots showing our outcome of interest on the x-axis and each numeric predictor on the y-axis.
# Check the distribution of continuous predictors. Outcome is "season"
(numeric_var <- select_if(d, is.numeric) %>% names()) # These are the numeric variables## [1] "CasesAll" "Deaths" "EndMonth"
## [4] "Hospitalizations" "MeanD1" "MeanI1"
## [7] "MedianD1" "MedianI1" "OBYear"
## [10] "RateAll" "RiskAll" "StartMonth"ridge_list <- list()
for(i in numeric_var) {
ridge_list[[i]] <- ggplot(data = d[, c("season", i)], aes_string(x = i, y = "season", color = "season", fill = "season")) +
geom_density_ridges(alpha = 0.4) +
labs(x = i) +
theme_bw() +
theme(legend.position = "none")
}
do.call("grid.arrange", c(ridge_list, ncol=3, top = "Distribution of continuous variables, color-coded by season"))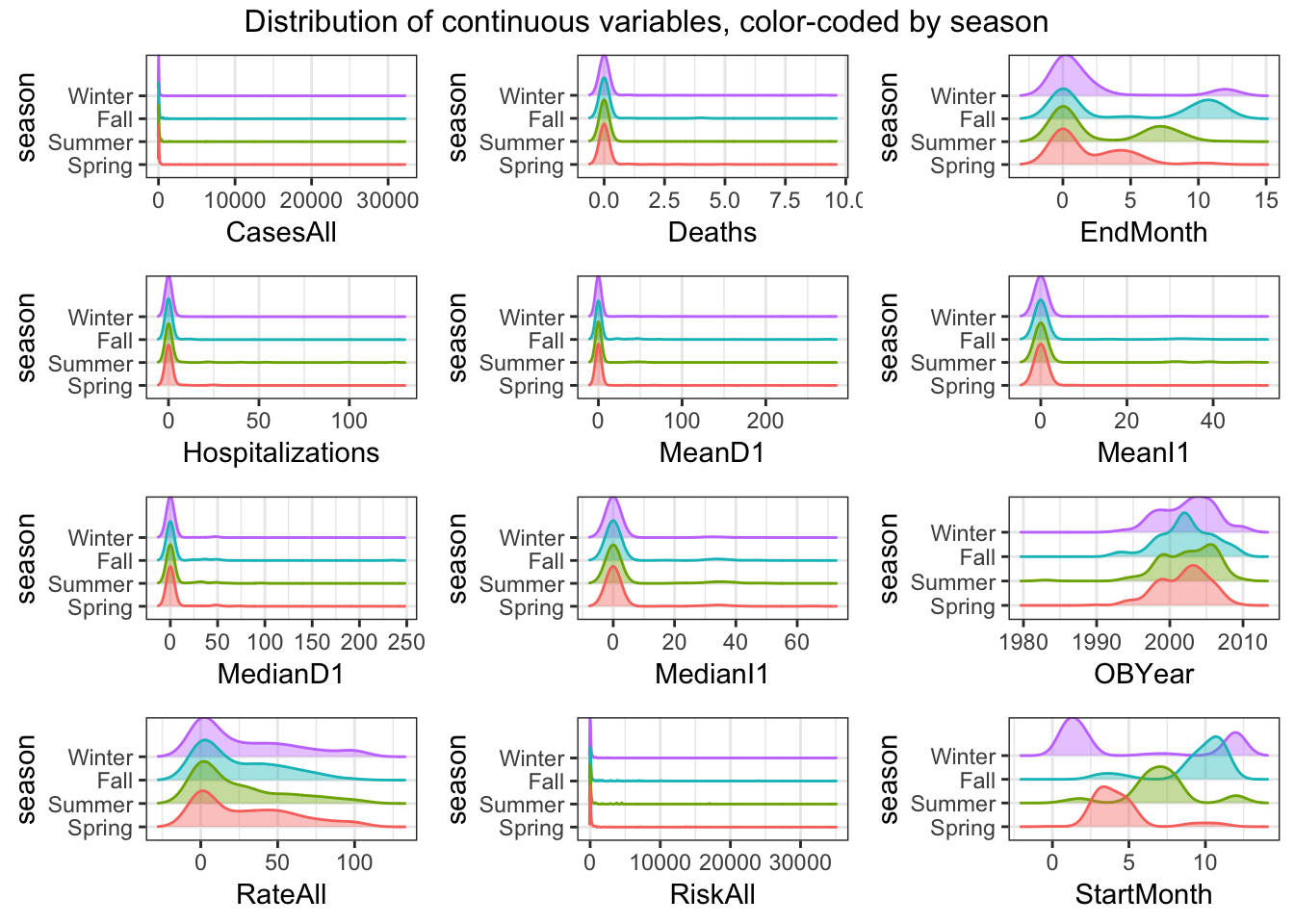
# Box plots of continuous predictors
box_list <- list()
for(i in numeric_var) {
box_list[[i]] <- ggplot(data = d[, c("season", i)], aes_string(y = i, x = "season", color = "season")) +
geom_boxplot() +
labs(y = i) +
theme_bw() +
theme(legend.position = "none")
}
do.call("grid.arrange", c(box_list, ncol=3, top = "Box plots of continuous variables, color-coded by season"))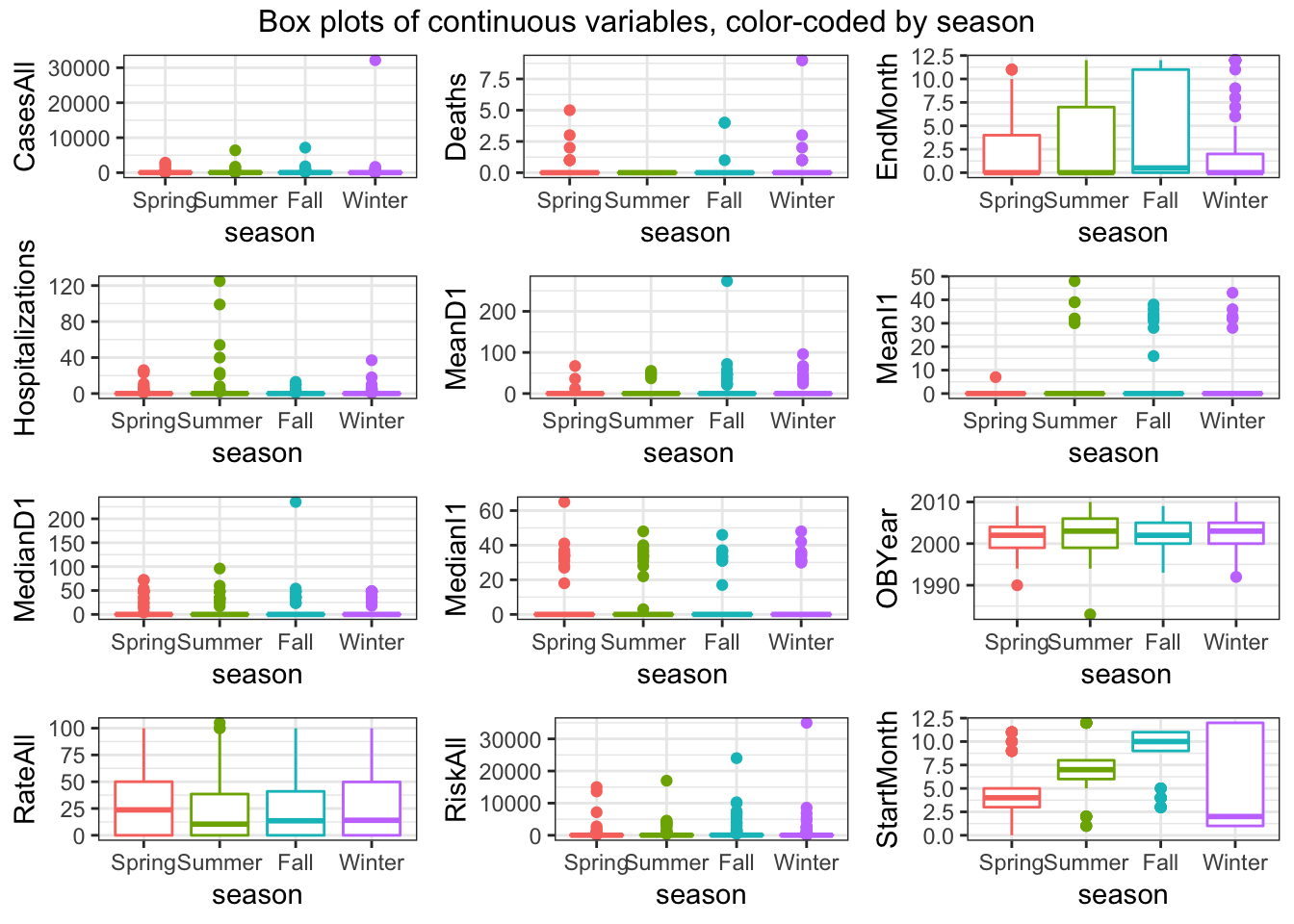
# Violin plots of continuous predictors
violin_list <- list()
for(i in numeric_var) {
violin_list[[i]] <- ggplot(data = d[, c("season", i)], aes_string(y = i, x = "season", color = "season")) +
geom_violin() +
geom_jitter(alpha = 0.2, width = 0.1) +
labs(y = i) +
theme_bw() +
theme(legend.position = "none")
}
do.call("grid.arrange", c(violin_list, ncol=3, top = "Violin plots of continuous variables, color-coded by season"))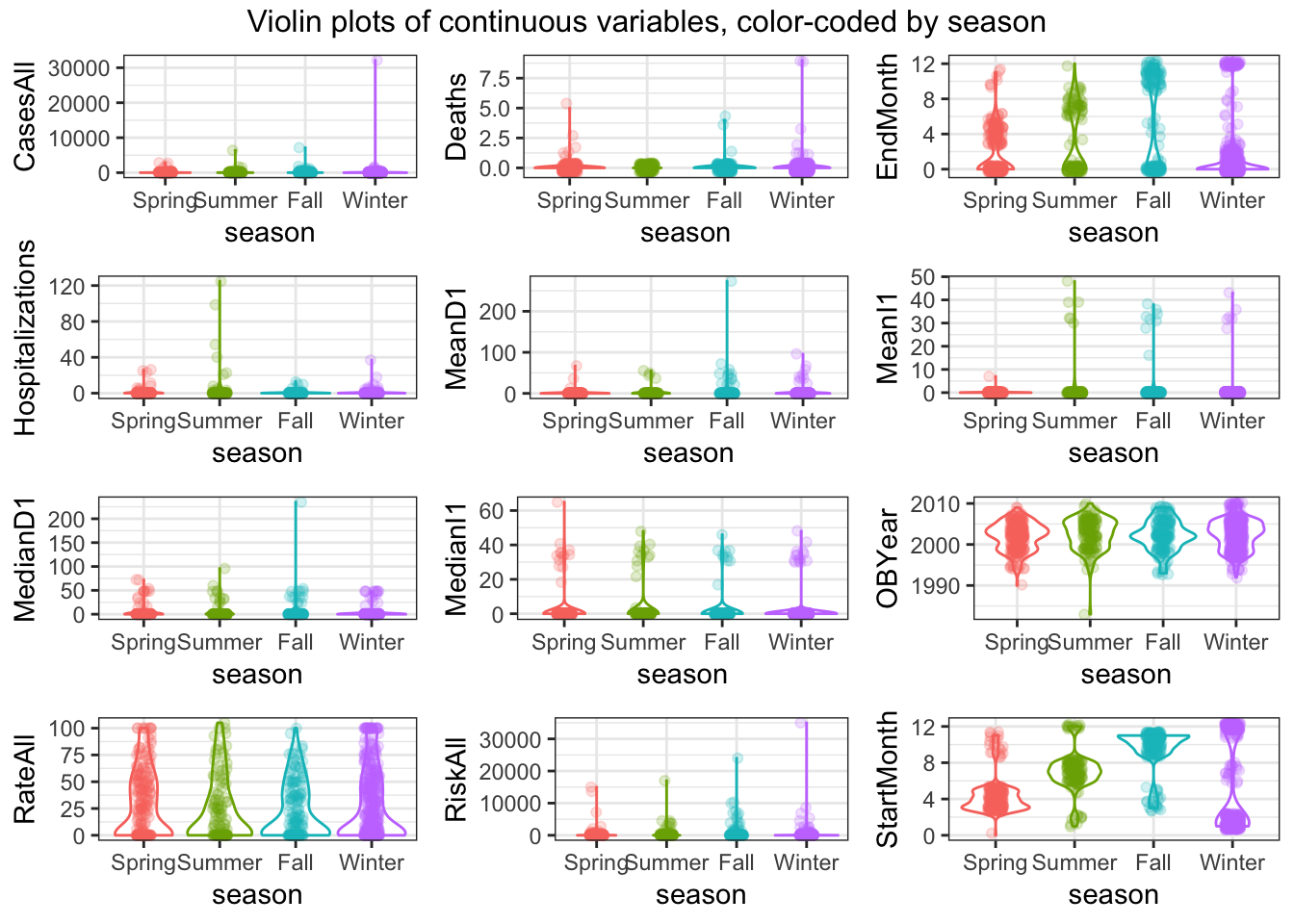
Notes:
Distribution of “EndMonth” is bimodal for all seasons
Distribution of “StartMonth” is multi-model for all seasons
- A lot of predictors are left-skewed Things look ok, apart from the skew in the predictors we discussed previously.
Next, let’s create plots for the categorical variables. You can use, for instance, geom_count for it, or some other representation. If you prefer lots of tables, that’s ok too.
#write code that produces plots or tables showing our outcome of interest and each categorical predictor.
(categ_var <- select_if(d, is.factor) %>% names())## [1] "season" "Action1" "Country" "gg2c4" "Hemisphere"
## [6] "Path1" "Setting_1" "Trans1" "Vomit"categ_var <- categ_var[categ_var != "season"]
# Tables of categorical predictors
for(i in categ_var) {
print(kable(table(d[[i]], d[["season"]]), caption = paste0("Count of ", i, " by season")))
}##
##
## Table: Count of Action1 by season
##
## Spring Summer Fall Winter
## ------------ ------- ------- ----- -------
## Unspecified 182 82 117 362
## Yes 40 43 47 79
##
##
## Table: Count of Country by season
##
## Spring Summer Fall Winter
## ------ ------- ------- ----- -------
## Japan 89 11 28 243
## Other 106 96 107 166
## USA 27 18 29 32
##
##
## Table: Count of gg2c4 by season
##
## Spring Summer Fall Winter
## ---- ------- ------- ----- -------
## No 177 96 103 300
## Yes 45 29 61 141
##
##
## Table: Count of Hemisphere by season
##
## Spring Summer Fall Winter
## --------- ------- ------- ----- -------
## Northern 202 104 144 422
## Southern 20 21 20 19
##
##
## Table: Count of Path1 by season
##
## Spring Summer Fall Winter
## ------------ ------- ------- ----- -------
## No 45 28 34 90
## Unspecified 158 81 115 323
## Yes 19 16 15 28
##
##
## Table: Count of Setting_1 by season
##
## Spring Summer Fall Winter
## ----------- ------- ------- ----- -------
## Other 179 109 137 339
## Restaurant 43 16 27 102
##
##
## Table: Count of Trans1 by season
##
## Spring Summer Fall Winter
## ----------------- ------- ------- ----- -------
## Environmental 18 27 9 29
## Foodborne 81 46 65 181
## Person to Person 41 21 28 60
## Unknown 22 7 7 27
## Unspecified 60 24 55 144
##
##
## Table: Count of Vomit by season
##
## Spring Summer Fall Winter
## --- ------- ------- ----- -------
## 0 114 50 81 224
## 1 108 75 83 216# Bar plots
bar_list <- list()
for(i in categ_var) {
bar_list[[i]] <- ggplot(data = d[, c("season", i)], aes(x = season)) +
geom_bar() +
labs(y = i) +
theme_bw() +
theme(legend.position = "none")
}
do.call("grid.arrange", c(bar_list, ncol=3, top = "Bar plots of categorical variables, by season"))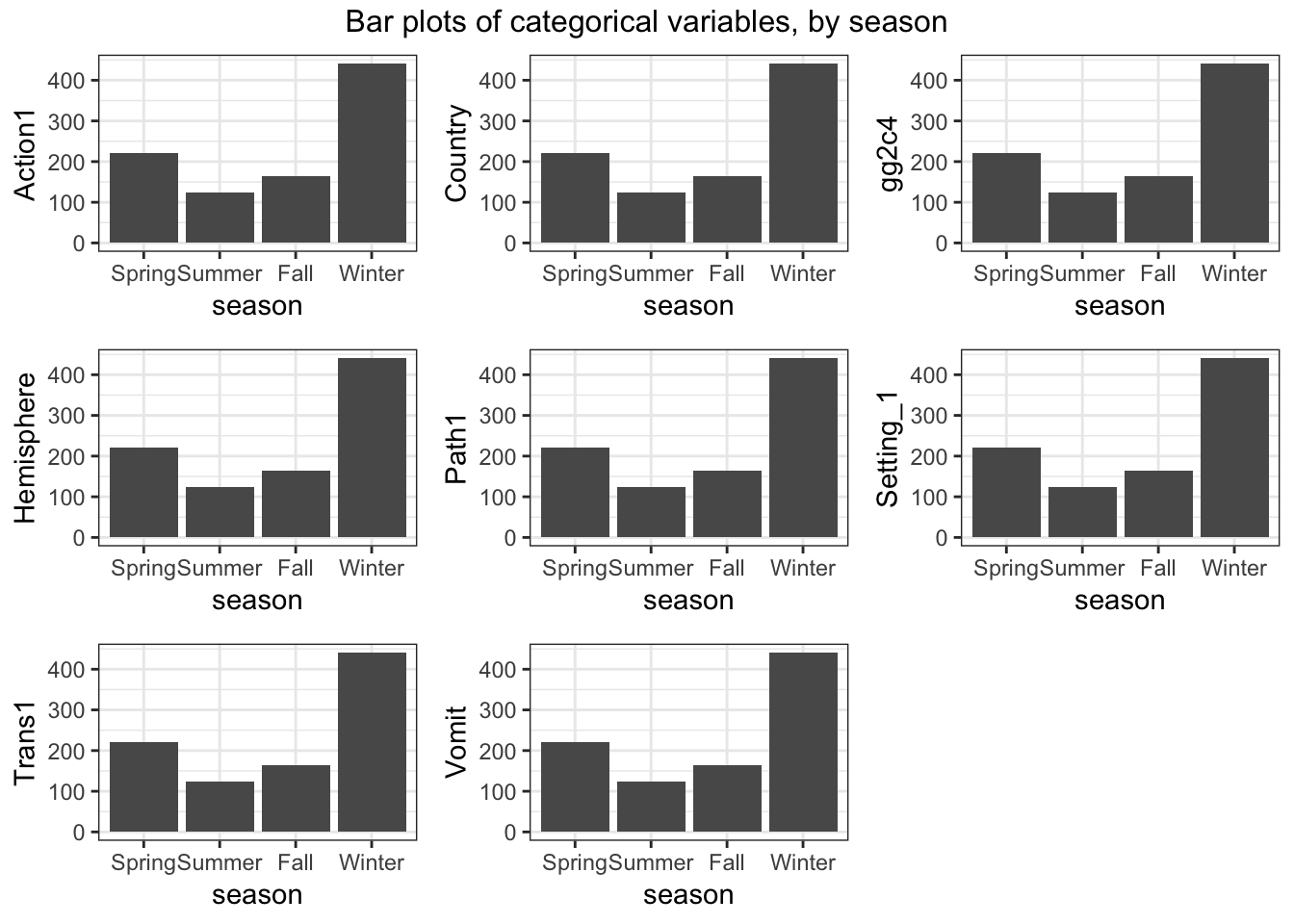
Looks ok. Notice the NA for vomiting. We are ok with that for now.
## [1] 952 21## 'data.frame': 952 obs. of 21 variables:
## $ season : Factor w/ 4 levels "Spring","Summer",..: 3 3 3 3 3 3 3 3 3 3 ...
## $ Action1 : Factor w/ 2 levels "Unspecified",..: 1 1 1 1 1 1 1 1 1 2 ...
## $ CasesAll : int 15 65 27 4 15 6 40 10 116 45 ...
## $ Country : Factor w/ 3 levels "Japan","Other",..: 1 3 2 2 2 2 2 2 2 3 ...
## $ Deaths : int 0 0 0 0 0 0 0 0 0 0 ...
## $ EndMonth : int 12 9 0 0 0 0 0 0 11 11 ...
## $ gg2c4 : Factor w/ 2 levels "No","Yes": 2 1 2 1 2 1 1 1 2 1 ...
## $ Hemisphere : Factor w/ 2 levels "Northern","Southern": 1 1 1 1 1 1 1 1 1 1 ...
## $ Hospitalizations: int 0 0 0 0 0 0 0 0 5 10 ...
## $ MeanD1 : num 0 0 0 0 0 0 0 0 0 0 ...
## $ MeanI1 : int 0 0 0 0 0 0 0 0 0 0 ...
## $ MedianD1 : num 0 36 0 0 0 0 0 0 0 48 ...
## $ MedianI1 : int 0 37 0 0 0 0 0 0 0 31 ...
## $ OBYear : int 1999 1998 2006 2006 2006 2006 2006 2006 2004 1993 ...
## $ Path1 : Factor w/ 3 levels "No","Unspecified",..: 1 1 2 2 2 2 2 2 1 2 ...
## $ RateAll : num 0 39.8 20.8 100 60 ...
## $ RiskAll : num 0 108 130 4 25 ...
## $ Setting_1 : Factor w/ 2 levels "Other","Restaurant": 1 1 1 2 1 2 1 2 1 1 ...
## $ StartMonth : int 11 9 9 10 11 11 11 11 11 11 ...
## $ Trans1 : Factor w/ 5 levels "Environmental",..: 5 2 2 2 2 2 2 2 5 2 ...
## $ Vomit : Factor w/ 2 levels "0","1": 2 2 2 2 2 2 2 2 2 2 ...At this step, you should have a dataframe containing 952 observations, and 21 variables: 1 outcome, 12 numeric/integer predictors, and 8 factor variables. All variables should have values that are ready for analysis. The outcome should be in the 1st slot.
Data splitting
Let’s do data splitting again. Use caret functions (or any other way you like) to split the data into 70/30 train/test portions.
#write code that splits data into 70/30 train/test
set.seed(123)
trainset <- caret::createDataPartition(y = d$season, p = 0.7, list = FALSE)
data_train = d[trainset,] #extract observations/rows for training, assign to new variable
data_test = d[-trainset,] #do the same for the test set
# Check it
dim(d)## [1] 952 21## [1] 668 21## [1] 284 21Parallelization
Similar to mlr, caret allows you to use multiple processors at the same time. It is easy to set up, and the few lines below do the trick.
Model fitting
We’ll now explore fitting and training several tree-based models. We’ll also explore how including/excluding missing values and centering/scaling or not might affect the results.
A null model
To define a null model, we need to determine what performance measure we want to track. Since we now have a categorical outcome with more than 2 categories, the regular 2x2 table/confusion matrix, and measurements that rely on it don’t quite work, though many of them have versions that go beyond the 2x2 table. To keep things simple, we will use accuracy, which is simply the fraction of correct predictions. It is easy to compute, no matter how many categories we have. The null model still predicts the most frequent category. We can use that as baseline performance.
#write code that computes accuracy for a null model that always predicts the most common category
summary(mod_null <- multinom(season ~ 1, data = d)) # I think we're being asked to do a null model for the logistic regression?## # weights: 8 (3 variable)
## initial value 1319.752232
## final value 1204.773441
## converged## Call:
## multinom(formula = season ~ 1, data = d)
##
## Coefficients:
## (Intercept)
## Summer -0.5744861
## Fall -0.3029044
## Winter 0.6865581
##
## Std. Errors:
## (Intercept)
## Summer 0.11183106
## Fall 0.10297199
## Winter 0.08229232
##
## Residual Deviance: 2409.547
## AIC: 2415.547predict_null <- predict(mod_null)
outcome <- d$season
(accur <- mean(outcome == predict_null)) # accuracy is 0.46## [1] 0.4632353## outcome
## Spring Summer Fall Winter
## 0.2331933 0.1313025 0.1722689 0.4632353You should find that the null model has an accuracy of around 0.46.
Single predictor models
Now let’s consider single predictor models, i.e., we’ll fit the outcome to each predictor one at a time to get an idea of the importance of individual predictors. Here, our model will be a tree. I’m actually not so sure if this makes a lot of sense since a “tree” with only one predictor seems a bit silly. But I guess we can try. It’s similar to a 1-predictor GLM.
We’ll also do some parameter tuning here. Looking at the caret documentation, we find that the tuning parameter for the rpart model (which is the tree algorithm) is called cp. We could also find that using modelLookup("rpart"). We could either specify a grid of values to try for cp (we’ll use a grid below), or, for a single tuning parameter, caret allows one to set the number of values to try and picks those values automatically. We’ll do the latter approach here.
#There is probably a nicer tidyverse way of doing this. I just couldn't think of it, so did it this way.
set.seed(1111) #makes each code block reproducible
outcomename = "season"
fitControl <- trainControl(method="repeatedcv",number=5,repeats=5) #setting CV method for caret
Npred <- ncol(data_train)-1 # number of predictors
resultmat <- data.frame(Variable = names(data_train)[-1], Accuracy = rep(0,Npred)) #store performance for each variable
for (n in 2:ncol(data_train)) #loop over each predictor. For this to work, outcome must be in 1st column
{
fit1 <- caret::train( as.formula(paste(outcomename, "~",names(data_train)[n])) , data = data_train, method = "rpart", trControl = fitControl, na.action = na.pass, tuneLength = 10)
resultmat[n-1,2]= max(fit1$results$Accuracy)
}
print(resultmat)## Variable Accuracy
## 1 Action1 0.4625783
## 2 CasesAll 0.4523858
## 3 Country 0.4559635
## 4 Deaths 0.4595846
## 5 EndMonth 0.6283915
## 6 gg2c4 0.4625740
## 7 Hemisphere 0.4595819
## 8 Hospitalizations 0.4574768
## 9 MeanD1 0.4604835
## 10 MeanI1 0.4578015
## 11 MedianD1 0.4544713
## 12 MedianI1 0.4529942
## 13 OBYear 0.4616846
## 14 Path1 0.4625800
## 15 RateAll 0.4622732
## 16 RiskAll 0.4739667
## 17 Setting_1 0.4625823
## 18 StartMonth 0.9011771
## 19 Trans1 0.4559836
## 20 Vomit 0.4625824So it looks like most of the single predictor models don’t have accuracy much better than the null. 2 exceptions are StartMonth and EndMonth. Well, we would expect that the outbreak season and the month at which the outbreak started (and ended) have a strong correlation. I kept those variables here to see if that would happen and get some reassurance that our model works ok. Of course, in a real analysis, keeping those seems silly, we wouldn’t learn much from it (other than data entry appeared to have been done ok).
Full model
Anyway, now let’s fit a tree to the full model with all predictors.
set.seed(1111) #makes each code block reproducible
fitControl <- trainControl(method="repeatedcv",number=5,repeats=5)
fit1 = caret::train(season ~ ., data=data_train, method="rpart", trControl = fitControl, na.action = na.pass, tuneLength = 10)
print(fit1$results)## cp Accuracy Kappa AccuracySD KappaSD
## 1 0.00000000 0.9748780 0.9632995 0.01773415 0.02581931
## 2 0.02181987 0.9745795 0.9627771 0.01864173 0.02742160
## 3 0.04363974 0.9147405 0.8756817 0.02620009 0.03792063
## 4 0.06545961 0.9012379 0.8558006 0.02304202 0.03322384
## 5 0.08727948 0.9012379 0.8558006 0.02304202 0.03322384
## 6 0.10909935 0.9012379 0.8558006 0.02304202 0.03322384
## 7 0.13091922 0.9012379 0.8558006 0.02304202 0.03322384
## 8 0.15273909 0.9012379 0.8558006 0.02304202 0.03322384
## 9 0.17455896 0.9012379 0.8558006 0.02304202 0.03322384
## 10 0.19637883 0.6993747 0.4826243 0.18511408 0.37438160This printout shows us model performance for different values of the tuning parameter, cp. It seems for a high cp, we get a close to perfect model. Let’s take a look at this model. We could use the regular plot function, but the resulting tree looks ugly. The prp function from the rpart.plot package makes a much nicer tree (other packages to plot nice trees exist).
I don’t quite understand the comment about a high cp yielding a near perfect model. To me it looks like th lowest cp’s (0 and 0.02) have the highest accuracy.

ww=17.8/2.54; wh=ww; #for saving plot
dev.print(device=png,width=ww,height=wh,units="in",res=600,file="rparttree.png") #save tree to file## quartz_off_screen
## 2So the model splits on month, repeatedly. And it also splits on the hemisphere, which makes sense since the seasons are switched in the Southern hemisphere. This is also likely the reason why the model with month only didn’t produce a perfect fit. It could get one hemisphere right, but not both. With both bits of information, we can get almost perfect predictions.
Note two distinguishing features of this tree model: Even though we fed the algorithm the full model including all predictor variables, some - in fact, almost all - of them are not part of the final model. This is a good illustration of the feature/variable selection property that a tree does automatically. If it doesn’t find a certain predictor variable useful, it leaves it out.
Also, note that some predictor variables are used more than once. In fact, in this example, only 2 variables are used, and they are used repeatedly.
You can also see on each node the predictions for each outcome category at that step. It is always possible to build a tree that predicts perfectly, but that would lead to overfitting. That’s why we use cross-validation and tuning of the cp parameter, which reduces the risk of overfitting.
Finally, note that by default, levels are ordered alphabetically (Fall/Spring/Summer/Winter). We could re-order the factor manually in the more logical Spring/Summer/Fall/Winter order. I would do that for a ‘real’ analysis where I want to show a nice final result, but here we can leave it as is, as long as we pay attention to this fact.
Re-fitting the tree
So the above produces an almost perfect fit, and thus more powerful models are not really needed. However, using start (and end) month information seems a bit like cheating. Of course, if we give the model that kind of information, it will do well. Let’s make it harder and remove those 2 variables from both the training and test sets.
Also, further below, I had problems fitting some of the models, the NA caused problems. The issue often is that while the underlying algorithm can handle the missing values (as you saw above), when using wrappers like caret, things break down. I could either skip caret and try to access the different models directly. For now, I decided to go the other route and drop the data with the missing values. To be able to compare the different models below, I’m dropping those NA observations here. Since the data changed, we also need to re-do the null model computation to be able to compare properly.
#write code that removes StartMonth and EndMonth from both training and test sets
data_train$StartMonth <- NULL
data_train$EndMonth <- NULL
data_test$StartMonth <- NULL
data_test$EndMonth <- NULL
# then drop all observations with missing values in both trian and test sets
data_train <- data_train[complete.cases(data_train), ]
summary(data_train) # no more NA's## season Action1 CasesAll Country
## Spring:130 Unspecified:426 Min. : 1.0 Japan:209
## Summer: 74 Yes :130 1st Qu.: 9.0 Other:278
## Fall : 95 Median : 25.0 USA : 69
## Winter:257 Mean : 152.5
## 3rd Qu.: 69.0
## Max. :32150.0
## Deaths gg2c4 Hemisphere Hospitalizations
## Min. :0.00000 No :392 Northern:517 Min. : 0.0000
## 1st Qu.:0.00000 Yes:164 Southern: 39 1st Qu.: 0.0000
## Median :0.00000 Median : 0.0000
## Mean :0.02878 Mean : 0.4658
## 3rd Qu.:0.00000 3rd Qu.: 0.0000
## Max. :4.00000 Max. :54.0000
## MeanD1 MeanI1 MedianD1 MedianI1
## Min. : 0.000 Min. : 0.000 Min. : 0.000 Min. : 0.000
## 1st Qu.: 0.000 1st Qu.: 0.000 1st Qu.: 0.000 1st Qu.: 0.000
## Median : 0.000 Median : 0.000 Median : 0.000 Median : 0.000
## Mean : 1.517 Mean : 0.795 Mean : 2.849 Mean : 2.092
## 3rd Qu.: 0.000 3rd Qu.: 0.000 3rd Qu.: 0.000 3rd Qu.: 0.000
## Max. :96.000 Max. :48.000 Max. :72.000 Max. :48.000
## OBYear Path1 RateAll RiskAll
## Min. :1983 No :124 Min. : 0.00 Min. : 0.0
## 1st Qu.:1999 Unspecified:402 1st Qu.: 0.00 1st Qu.: 0.0
## Median :2002 Yes : 30 Median : 13.92 Median : 19.0
## Mean :2002 Mean : 25.82 Mean : 389.7
## 3rd Qu.:2005 3rd Qu.: 48.04 3rd Qu.: 108.2
## Max. :2010 Max. :100.00 Max. :24000.0
## Setting_1 Trans1 Vomit
## Other :436 Environmental : 55 0:265
## Restaurant:120 Foodborne :233 1:291
## Person to Person: 78
## Unknown : 44
## Unspecified :146
## ## season Action1 CasesAll Country
## Spring: 57 Unspecified:199 Min. : 1.00 Japan:107
## Summer: 29 Yes : 40 1st Qu.: 7.00 Other:104
## Fall : 40 Median : 20.00 USA : 28
## Winter:113 Mean : 85.38
## 3rd Qu.: 53.00
## Max. :6390.00
## Deaths gg2c4 Hemisphere Hospitalizations
## Min. :0.0000 No :168 Northern:225 Min. : 0.0000
## 1st Qu.:0.0000 Yes: 71 Southern: 14 1st Qu.: 0.0000
## Median :0.0000 Median : 0.0000
## Mean :0.1172 Mean : 0.8787
## 3rd Qu.:0.0000 3rd Qu.: 0.0000
## Max. :9.0000 Max. :99.0000
## MeanD1 MeanI1 MedianD1 MedianI1
## Min. : 0.000 Min. : 0.0000 Min. : 0.000 Min. : 0.000
## 1st Qu.: 0.000 1st Qu.: 0.0000 1st Qu.: 0.000 1st Qu.: 0.000
## Median : 0.000 Median : 0.0000 Median : 0.000 Median : 0.000
## Mean : 1.134 Mean : 0.6987 Mean : 1.594 Mean : 1.259
## 3rd Qu.: 0.000 3rd Qu.: 0.0000 3rd Qu.: 0.000 3rd Qu.: 0.000
## Max. :67.000 Max. :36.0000 Max. :60.000 Max. :65.000
## OBYear Path1 RateAll RiskAll
## Min. :1992 No : 46 Min. : 0.00 Min. : 0.0
## 1st Qu.:1999 Unspecified:183 1st Qu.: 0.00 1st Qu.: 0.0
## Median :2002 Yes : 10 Median : 17.86 Median : 20.0
## Mean :2002 Mean : 30.56 Mean : 175.5
## 3rd Qu.:2005 3rd Qu.: 55.78 3rd Qu.: 97.5
## Max. :2010 Max. :105.00 Max. :6851.0
## Setting_1 Trans1 Vomit
## Other :187 Environmental :17 0:125
## Restaurant: 52 Foodborne :90 1:114
## Person to Person:28
## Unknown :17
## Unspecified :87
## ## [1] 0.3006289# copy and paste the code from above that computes performance of a null model
revised_d <- rbind(data_train, data_test)
summary(mod_null <- multinom(season ~ 1, data = revised_d)) # I think we're being asked to do a null model for the logistic regression?## # weights: 8 (3 variable)
## initial value 1102.104017
## iter 10 value 1003.488080
## final value 1003.479377
## converged## Call:
## multinom(formula = season ~ 1, data = revised_d)
##
## Coefficients:
## (Intercept)
## Summer -0.5963798
## Fall -0.3258337
## Winter 0.6823945
##
## Std. Errors:
## (Intercept)
## Summer 0.12270425
## Fall 0.11293804
## Winter 0.08972344
##
## Residual Deviance: 2006.959
## AIC: 2012.959predict_null <- predict(mod_null)
outcome <- revised_d$season
(accur <- mean(outcome == predict_null)) # accuracy is 0.46## [1] 0.4654088## outcome
## Spring Summer Fall Winter
## 0.2352201 0.1295597 0.1698113 0.4654088You should find a very similar null-model accuracy, around 0.46.
Now, let’s re-do the fit above fitting a single tree. I’ll increase the tuneLength value a bit so the algorithm can try a few more parameter values.
#copy and paste the code from above that fits the single tree. set tuneLength to 20.
set.seed(1111) #makes each code block reproducible
fitControl <- trainControl(method="repeatedcv",number=5,repeats=5)
rpart_fit2 = caret::train(season ~ ., data=data_train, method="rpart", trControl = fitControl, na.action = na.pass, tuneLength = 20)
# look at model performance for different cp values. Also plot the tree.
print(rpart_fit2$results) # The final value used for the model was cp = 0.01742651.## cp Accuracy Kappa AccuracySD KappaSD
## 1 0.0000000000 0.4406906 0.14929009 0.04014181 0.06117116
## 2 0.0009681394 0.4406906 0.14929009 0.04014181 0.06117116
## 3 0.0019362788 0.4403335 0.14862047 0.04054011 0.06205869
## 4 0.0029044182 0.4417685 0.14791743 0.04090063 0.06122825
## 5 0.0038725576 0.4428399 0.14760886 0.03990468 0.06076178
## 6 0.0048406971 0.4449987 0.14621235 0.04019554 0.06076727
## 7 0.0058088365 0.4450051 0.14288192 0.03766741 0.06007901
## 8 0.0067769759 0.4514465 0.13967658 0.03689510 0.05911547
## 9 0.0077451153 0.4518068 0.13766475 0.03720265 0.05983752
## 10 0.0087132547 0.4517714 0.12175307 0.03535503 0.06031206
## 11 0.0096813941 0.4488885 0.11132721 0.03377926 0.06130327
## 12 0.0106495335 0.4489342 0.09190201 0.03110417 0.05750603
## 13 0.0116176729 0.4496581 0.08526367 0.03235586 0.06083704
## 14 0.0125858124 0.4507228 0.05218213 0.03051872 0.05052446
## 15 0.0135539518 0.4503624 0.04880457 0.03001709 0.04381689
## 16 0.0145220912 0.4532390 0.04328970 0.02651709 0.04337113
## 17 0.0154902306 0.4546937 0.03554787 0.02312313 0.03739328
## 18 0.0164583700 0.4561223 0.03059785 0.02161883 0.03584857
## 19 0.0174265094 0.4608037 0.02509599 0.01878758 0.04038019
## 20 0.0183946488 0.4597227 0.02116783 0.01800965 0.03765672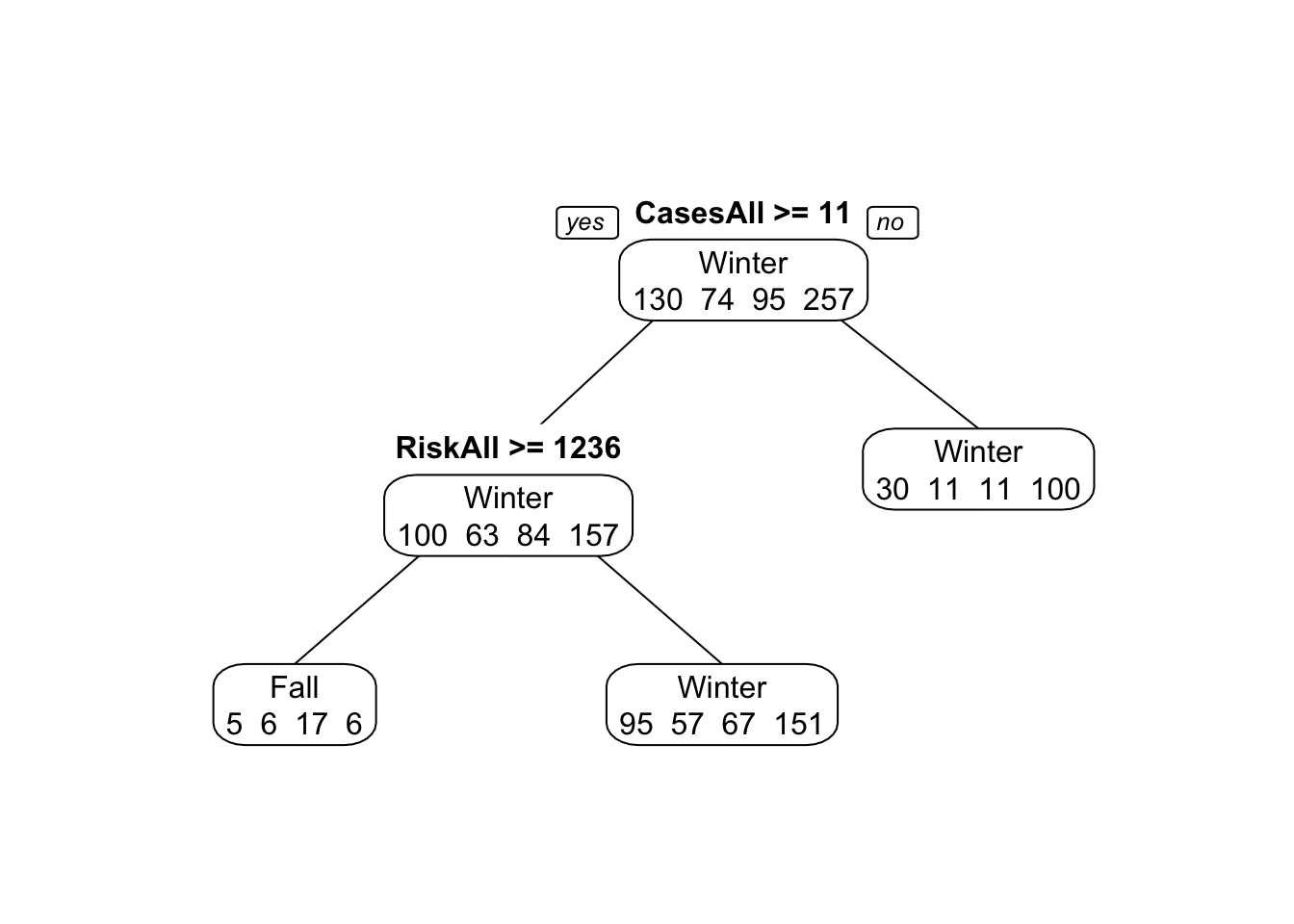
ww=17.8/2.54; wh=ww; #for saving plot
dev.print(device=png,width=ww,height=wh,units="in",res=600,file="rparttree_fit2.png") ## quartz_off_screen
## 2With those variables removed, the tree model doesn’t perform very well. Accuracy is similar to the null model. You can see that in the tree figure, the final nodes (leaves) show a lot of mis-predictions. Note again that only a few variables are used to build the tree, and OBYear shows up more than once.
Hmmm…. With the seed I set, my final tree doesn’t use OBYear at all. It only uses CasesAll and RiskAll. HOWEVER, when I run the model with a different seed I get OBYear as a predictor. So it seems that the model is so confused and poor that different runs will yield different sets of predictors, and the best accuracy will still be similar to the accuracy of the null model.
Let’s see if we can get improved performance with more complicated models. That is, of course, not guaranteed. If there is no “signal” in the data, it doesn’t matter how complicated the model is. We won’t get anything predictive.
Random forest
Let’s try a random forest. We’ll use the ranger algorithm for this (it’s generally faster than the rf algorithm). This model has parameters that can and should be tuned. To do the tuning, we set up a grid of parameters and search over that grid. More efficient ways exist, e.g., doing an optimization using something like a genetic algorithm. The mlr package allows you to do that, caret doesn’t have those features out of the box, you would need to write your own code for that.
Note that running the code below (and several models that follow) might take a few seconds or minutes, depending on the speed of your computer.
set.seed(1111) #makes each code block reproducible
tuning_grid <- expand.grid( .mtry = seq(1,7,by=1), .splitrule = "gini", .min.node.size = seq(2,8,by=1) )
ranger_fit2 = caret::train(season ~ ., data=data_train, method="ranger", trControl = fitControl, tuneGrid = tuning_grid, na.action = na.pass) We can’t plot a nice final tree anymore since the model is now a combination of trees. We can look at a plot of model performance as a function of the model tuning parameters.
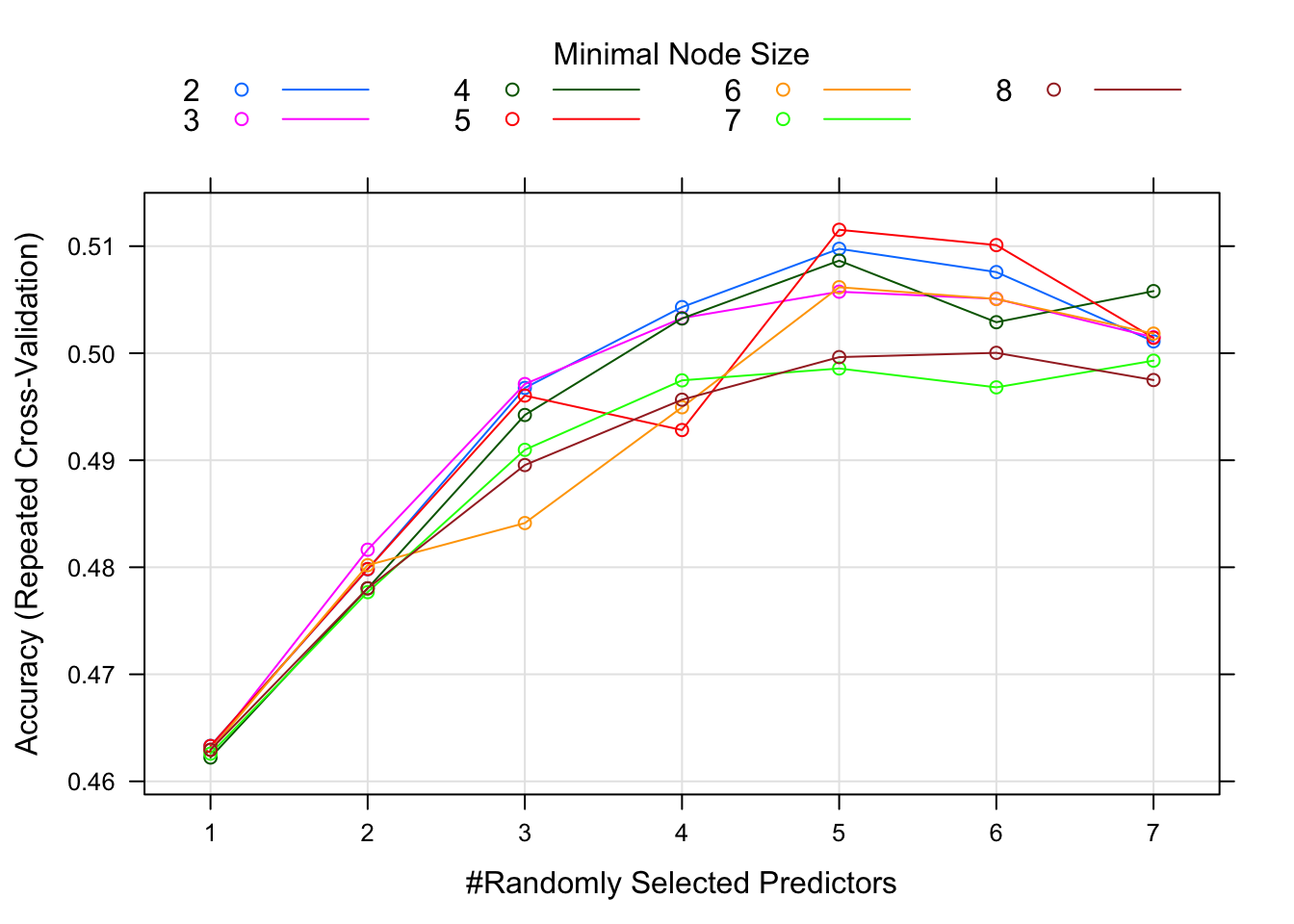
This plot suggests that for around 4 randomly selected parameters and a minimum node size of 6, we get the best model. Note that there isn’t much difference in model performance for several different values of the tuning parameters, and the overall model isn’t that great either, an accuracy just shy of 0.5.
In my model, the best accuracy was for 5 randomly selected parameters and a minimum mode size of 5. Best accuracy was just a bit over 0.51.
Boosted tree ensemble
Let’s now try a boosted regression tree ensemble. This method also has several parameters that need tuning, which are specified in gbmGrid.
gbmGrid <- expand.grid(interaction.depth = seq(1, 7, by = 2), n.trees = 300, shrinkage = c(0.1, 0.01), n.minobsinnode = c(2,4,6))
gbm_fit3 = caret::train(season ~ ., data=data_train, method="gbm", trControl = fitControl, verbose=FALSE, tuneGrid = gbmGrid) We can again look at diagnostic fits and variable importance plots for this model, as well as check performance.
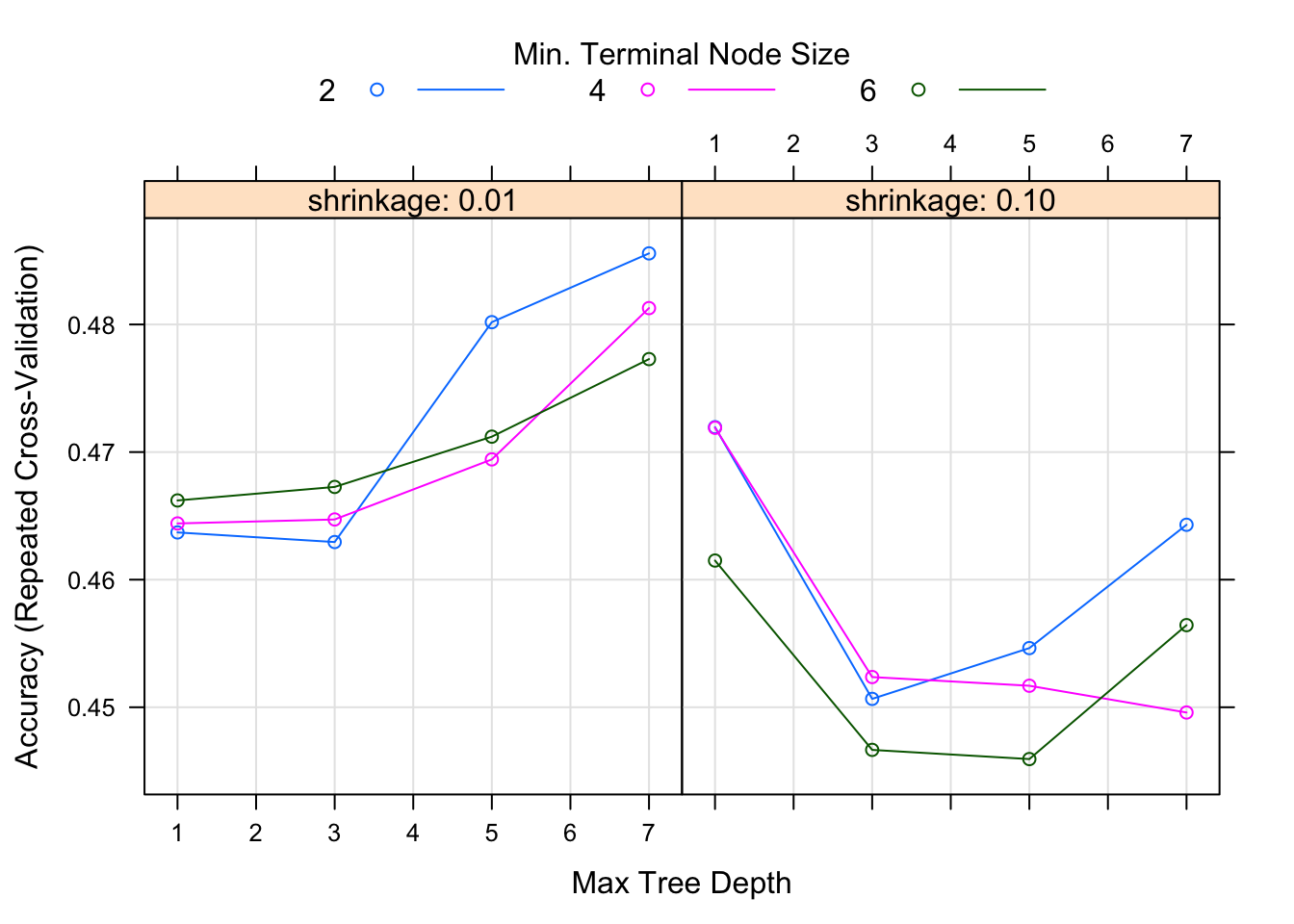
It doesn’t look like the boosted tree model performs any better. It may be that no information in the predictors strongly correlates with the season.
But let’s not give up yet, we’ll try a bit more. Let’s see if pre-processing helps.
Random forest with pre-processed predictors
Here, we’ll fit another random forest model but now use centering and scaling for the predictors.
# copy the random forest code from above. Add a statement to the train() function that centers and scales predictors.
set.seed(1111) #makes each code block reproducible
tuning_grid <- expand.grid( .mtry = seq(1,7,by=1), .splitrule = "gini", .min.node.size = seq(2,8,by=1) )
fit4 = caret::train(season ~ ., data=data_train, method="ranger", preProcess = c("center", "scale"), trControl = fitControl, tuneGrid = tuning_grid, na.action = na.pass)
# save the result as fit4. plot model results.
plot(fit4)
It doesn’t look like it helped a lot.
Discriminant analysis
Ok, let’s try one more. Since the trees don’t seem to work too well, and a logistic model doesn’t work for multiple categorical outcomes, let’s use another model that can do that, namely a discriminant analysis. We’ve already seen one of those previously. Let’s pick a different one. The caret package website lists a lot of algorithms. I don’t know how exactly they all differ. Let’s try the one called penalized discriminant analysis (pda) (penalized is another way of saying regularized, and we learned that regularization might sometimes help.)
#write code that trains a pda model, use tuneLength 20. Save as fit5 and plot.
set.seed(1111)
(fit5 = caret::train(season ~ ., data=data_train, method="pda", trControl = fitControl, na.action = na.pass, tuneLength = 20))## Penalized Discriminant Analysis
##
## 556 samples
## 18 predictor
## 4 classes: 'Spring', 'Summer', 'Fall', 'Winter'
##
## No pre-processing
## Resampling: Cross-Validated (5 fold, repeated 5 times)
## Summary of sample sizes: 445, 446, 444, 445, 444, 444, ...
## Resampling results across tuning parameters:
##
## lambda Accuracy Kappa
## 0.0000000000 0.4510050 0.1356895
## 0.0001000000 0.4510050 0.1356895
## 0.0001467799 0.4510050 0.1356895
## 0.0002154435 0.4510050 0.1356895
## 0.0003162278 0.4510050 0.1356895
## 0.0004641589 0.4510050 0.1356895
## 0.0006812921 0.4510050 0.1356895
## 0.0010000000 0.4510050 0.1356895
## 0.0014677993 0.4510050 0.1356895
## 0.0021544347 0.4510050 0.1356895
## 0.0031622777 0.4510050 0.1356895
## 0.0046415888 0.4510050 0.1356895
## 0.0068129207 0.4510050 0.1356895
## 0.0100000000 0.4506479 0.1350086
## 0.0146779927 0.4506479 0.1348850
## 0.0215443469 0.4506479 0.1348850
## 0.0316227766 0.4506479 0.1348850
## 0.0464158883 0.4502875 0.1341719
## 0.0681292069 0.4506479 0.1345958
## 0.1000000000 0.4506479 0.1344823
##
## Accuracy was used to select the optimal model using the largest value.
## The final value used for the model was lambda = 0.
Ok, that doesn’t look very good either. Alright, enough models, there just doesn’t seem to be much information in the data that could help predict season. So let’s start to wrap up.
Comparing model performance
To recap: After we removed the obvious predictors, we fitted 1 tree, 1 random forest, 1 gradient boosted tree, 1 random forest with processed predictors, and 1 discriminant analysis. Let’s compare the performance.
resamps <- resamples(list(tree = rpart_fit2,
RF1 = ranger_fit2,
GBM = gbm_fit3,
RF2 = fit4,
PDA = fit5))
bwplot(resamps)
This plot suggests that while none of the models are great, the random forest ones seem overall slightly better.
Evaluating the final model
Even though we didn’t really have any good model, and thus further evaluating it seems, in some sense pointless, for this exercise we’ll look at our “best” model anyway. We’ll declare the 1st random forest model (saved as fit2) to be the best.
Model uncertainty in the predictions is shown in the previous plot.
For categorical outcomes, we can’t plot residuals. But we can look at the final “2x2” (in this case, a 4x4) table (the confusion matrix) and compare true versus predicted outcomes and see if it shows any pattern.
#Write code to get model predictions for the outcome on the training data.
data_train$PredictRF <- predict(ranger_fit2)
#use predicted and actual outcomes, make a table and compute accuracy.
data_train = apply_labels(data_train,
PredictRF = "Predicted Season (random forest)",
season = "Actual Season")
(acc_table <- cro(data_train$PredictRF, data_train$season))| Actual Season | ||||
|---|---|---|---|---|
| Spring | Summer | Fall | Winter | |
| Predicted Season (random forest) | ||||
| Spring | 109 | 1 | ||
| Summer | 64 | |||
| Fall | 3 | 4 | 82 | 1 |
| Winter | 18 | 5 | 13 | 256 |
| #Total cases | 130 | 74 | 95 | 257 |
## [1] 0.9190647## Confusion Matrix and Statistics
##
## Reference
## Prediction Spring Summer Fall Winter
## Spring 109 1 0 0
## Summer 0 64 0 0
## Fall 3 4 82 1
## Winter 18 5 13 256
##
## Overall Statistics
##
## Accuracy : 0.9191
## 95% CI : (0.8932, 0.9404)
## No Information Rate : 0.4622
## P-Value [Acc > NIR] : < 2.2e-16
##
## Kappa : 0.8788
##
## Mcnemar's Test P-Value : 2.544e-07
##
## Statistics by Class:
##
## Class: Spring Class: Summer Class: Fall Class: Winter
## Sensitivity 0.8385 0.8649 0.8632 0.9961
## Specificity 0.9977 1.0000 0.9826 0.8796
## Pos Pred Value 0.9909 1.0000 0.9111 0.8767
## Neg Pred Value 0.9529 0.9797 0.9721 0.9962
## Prevalence 0.2338 0.1331 0.1709 0.4622
## Detection Rate 0.1960 0.1151 0.1475 0.4604
## Detection Prevalence 0.1978 0.1151 0.1619 0.5252
## Balanced Accuracy 0.9181 0.9324 0.9229 0.9379Accuracy is 0.92
You should see that the model gets a lot right (high numbers on the diagonal), but predicts winter more often than it should (last row). Accuracy in the training data is pretty good.
But we know that performance on the training set is not that meaningful, especially with a complex model we always get fairly good performance on the data used to build the model. What matters is how it performs on new data, so let’s check that. We can look at the same for the test set, which is a better estimate of the true performance.
#copy and paste the code from above, but now do it for the test set.
set.seed(1111) #makes each code block reproducible
tuning_grid <- expand.grid( .mtry = seq(1,7,by=1), .splitrule = "gini", .min.node.size = seq(2,8,by=1) )
ranger_test_fit2 = caret::train(season ~ ., data=data_test, method="ranger", trControl = fitControl, tuneGrid = tuning_grid, na.action = na.pass)
plot(ranger_test_fit2)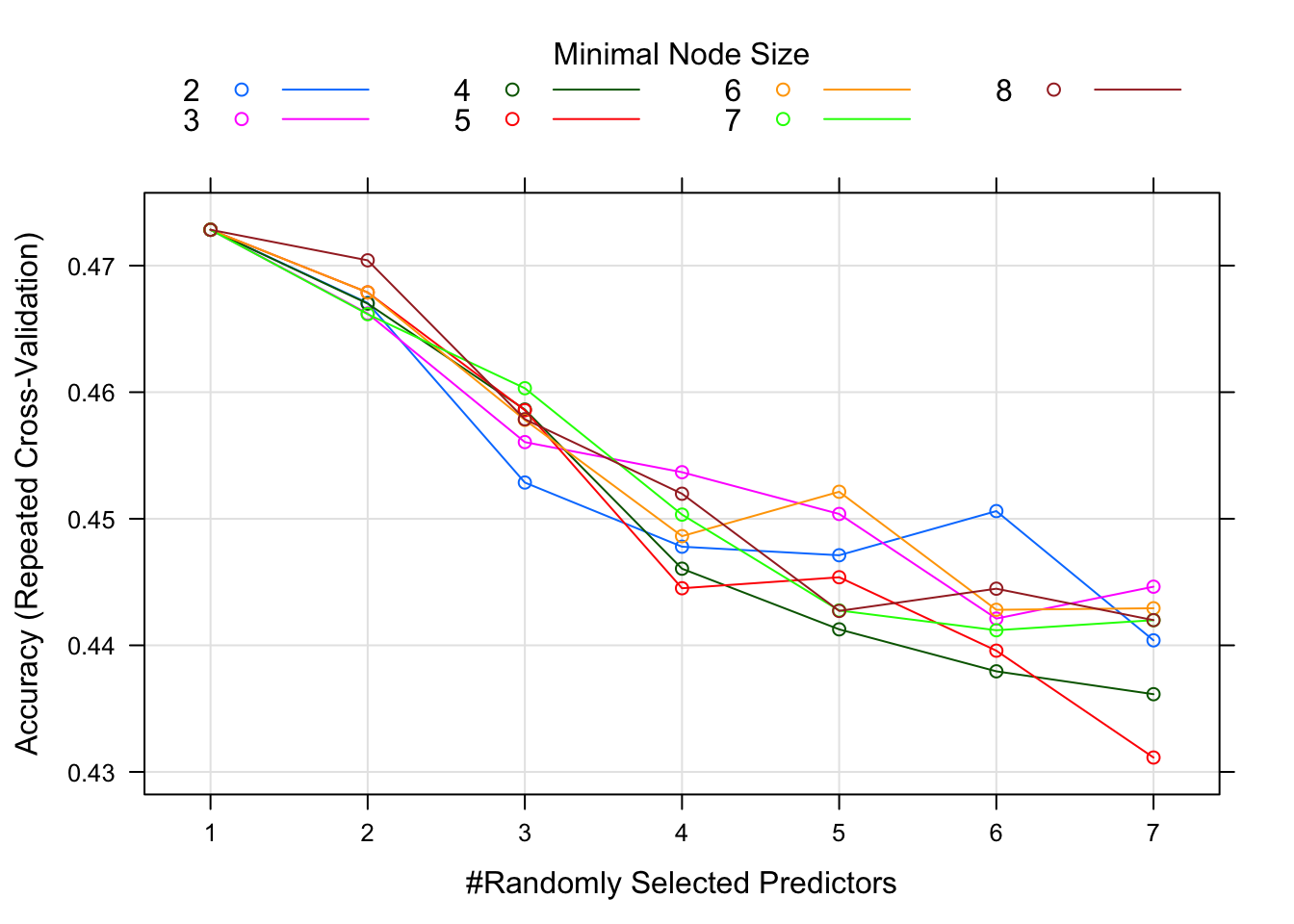
# get model predictions
data_test$PredictRF <- predict(ranger_test_fit2)
#use predicted and actual outcomes, make a table and compute accuracy.
data_test = apply_labels(data_test,
PredictRF = "Predicted Season (random forest)",
season = "Actual Season")
(acc_table_test <- cro(data_test$PredictRF, data_test$season))| Actual Season | ||||
|---|---|---|---|---|
| Spring | Summer | Fall | Winter | |
| Predicted Season (random forest) | ||||
| Spring | 1 | |||
| Summer | ||||
| Fall | ||||
| Winter | 56 | 29 | 40 | 113 |
| #Total cases | 57 | 29 | 40 | 113 |
## [1] 0.4769874## Confusion Matrix and Statistics
##
## Reference
## Prediction Spring Summer Fall Winter
## Spring 1 0 0 0
## Summer 0 0 0 0
## Fall 0 0 0 0
## Winter 56 29 40 113
##
## Overall Statistics
##
## Accuracy : 0.477
## 95% CI : (0.4122, 0.5423)
## No Information Rate : 0.4728
## P-Value [Acc > NIR] : 0.4737
##
## Kappa : 0.0098
##
## Mcnemar's Test P-Value : NA
##
## Statistics by Class:
##
## Class: Spring Class: Summer Class: Fall Class: Winter
## Sensitivity 0.017544 0.0000 0.0000 1.000000
## Specificity 1.000000 1.0000 1.0000 0.007937
## Pos Pred Value 1.000000 NaN NaN 0.474790
## Neg Pred Value 0.764706 0.8787 0.8326 1.000000
## Prevalence 0.238494 0.1213 0.1674 0.472803
## Detection Rate 0.004184 0.0000 0.0000 0.472803
## Detection Prevalence 0.004184 0.0000 0.0000 0.995816
## Balanced Accuracy 0.508772 0.5000 0.5000 0.503968```
Here, the confusion matrix doesn’t look good at all. Off-diagonal entries are larger than diagonal, accuracy is about as good as a null model, and agrees with the cross-validated results. That last point is good, that means our cross-validation routine properly estimates the performance of “new” data. Of course, even this estimate on test data is a bit optimistic, since real new data is usually collected under slightly different circumstances and with different protocols, making it more likely that model performance is reduced.
Wrapping up
# shut down the parallel computing cluster we created at the beginning of the analysis
stopCluster(cl)Overall, this suggests there is just no “signal” in the variables we are trying to use to predict the outcome, and the model fits to “noise” - thus doing ok on training data but failing on the test/cross-validated performance evaluation.
We can conclude that this is an analysis where we walk away “empty handed”. If this were a real analysis and you had data and did a ‘let’s see if something is going on’ analysis, this would be somewhat disappointing. If you had a specific, plausible hypothesis before you started your analysis (e.g., that outbreak size is correlated with season), finding that your biologically reasonable hypothesis doesn’t seem to be right is useful. Unfortunately, null results are still hard to publish.
Note that we didn’t use p-values here, but I bet we would have found several that are statistically significant when evaluated on the training data (as they usually are). But they would be meaningless and essentially “fitting the noise”. I contend that a lot of what’s published out there is exactly that, spurious p-values because models are evaluated on the training data.
End notes
Above, I kept search grids relatively small and specified other things (e.g., number of trees) to make sure things run reasonably fast. For a real project, I would make my searches and tuning more exhaustive, which might mean waiting a few hours for the code to run. If you want to, try to increase the search space or try different models to see if you can get a better performing model. It doesn’t seem to me that the data has any meaningful signal that would lead to a great model with much-improved performance. But you are welcome to see if you can find a model that performs better. If you do get a model that performs well (>0.6 accuracy), let me know. I’d be curious to see it.